如何让 Claude Code 的长会话不失控
一篇实用指南:什么时候该用 /compact,什么时候该用 /clear,哪些信息该写进 CLAUDE.md,怎样避免长会话越聊越乱。
如何让 Claude Code 的长会话不失控
Claude Code 的长会话失控,通常不是随机发生的。
最常见的症状是:前面说过的重要规则开始丢,终端输出和试错过程把真正重要的信息冲掉了,Claude 记住了错误的上下文,却忘了你真正想保留的约束。很多人把这统称为“撞上 token 限制”,但更准确地说,问题往往是会话管理出了问题,而不只是 token 数字本身。
这篇文章不打算空讲 token 原理,而是直接回答几个实操问题:什么时候该用 /compact,什么时候该用 /clear,哪些信息应该写进 CLAUDE.md,怎样让长时间的调试和改代码会话依然保持清醒。
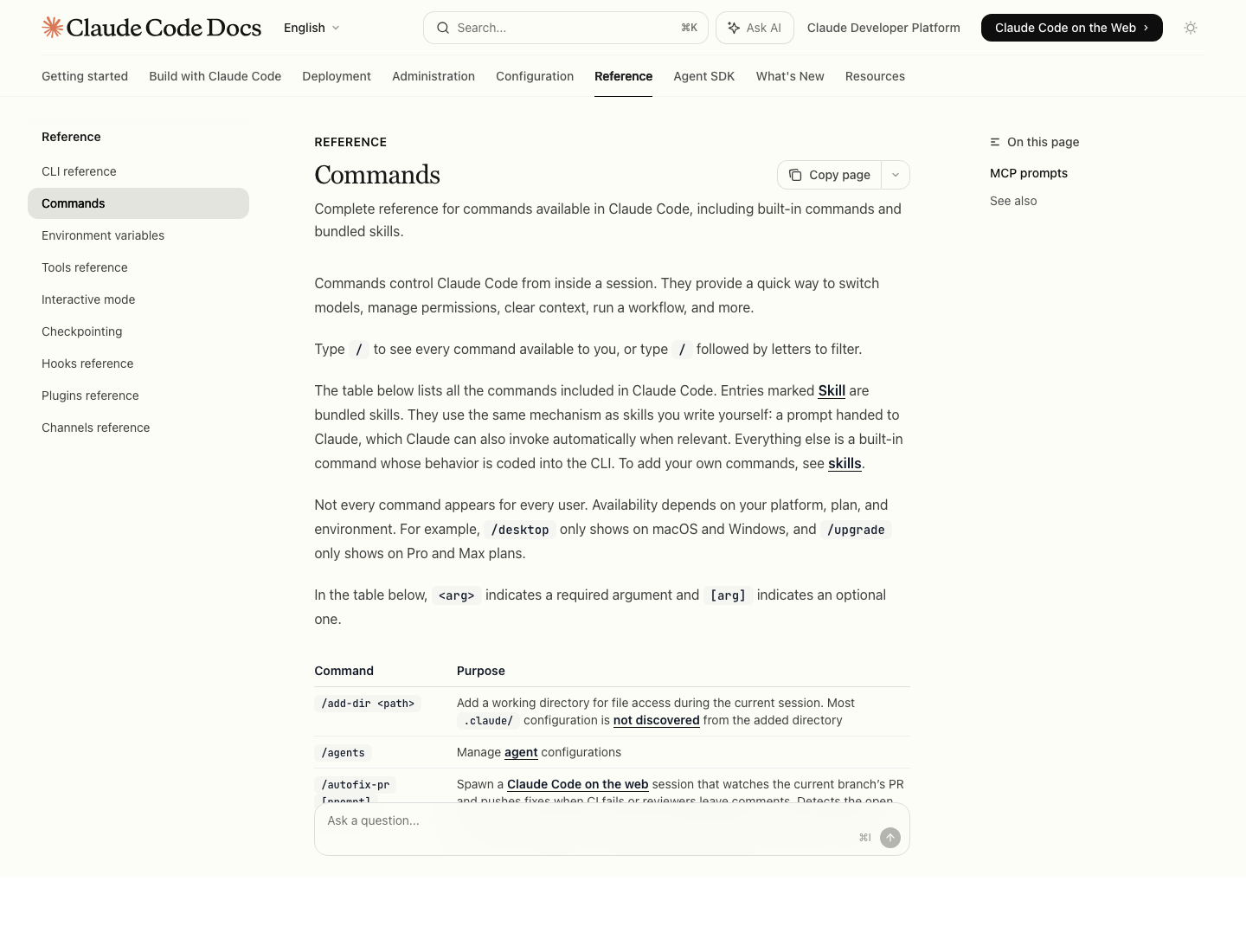
来源:Claude Code commands reference
到底是什么在消耗上下文
按照 Claude Code 官方文档的说法,上下文窗口里装的不只是聊天记录,还包括 Claude 读过的文件、命令输出、CLAUDE.md、auto memory、已加载的技能,以及系统指令。
所以长会话变差,通常至少有四种原因:
- 聊天本身已经太长了
- Claude 读进来了太多文件和终端输出
- 关键规则只存在于对话里,没有落盘到
CLAUDE.md - 一次性细节太多,开始和真正的任务抢上下文
重点不是“不要用上下文”,而是要把昂贵的上下文留给 20 轮之后依然应该重要的东西。
最该掌握的 4 个工具
/context
当你想知道“我是真的快满了,还是只是这轮会话太脏了”,先用 /context。
它能直接帮你看当前上下文使用情况。如果会话还很健康,那就继续;如果已经明显拥挤,就不要等质量掉下去之后再补救。
/compact
当任务还是同一个,但会话里已经积累了太多噪音时,用 /compact。
它的作用不是重开,而是压缩。Claude Code 官方文档也提到,系统会在需要时自动 compact,但手动 compact 往往更好,因为你可以明确告诉它哪些信息必须保留。
例如:
/compact keep the auth bug, the failing test, and the decision to preserve the old API response shape
/compact focus on the refactor plan, ignored experiments, and final file targets
/clear
当这段对话本身已经不值得继续背着走时,用 /clear。
典型场景:
- 你要切到一个完全不同的问题
- 当前这条线程已经聊乱了
- 之前走进了一个死胡同
- 你需要真正的干净起点
不要因为“会话有点长”就立刻 /clear。只有当连续性已经不值钱,清晰度才应该优先。
/memory
当问题不在“这一轮对话”,而在“你每天都要重复解释同一件事”时,用 /memory。
这里才是你审视 CLAUDE.md、查看当前加载的 memory 文件、管理 auto memory 的地方。如果你总是在重复 build 命令、测试前置条件、项目规则,那答案通常不是继续在聊天里重复,而是写进记忆系统。
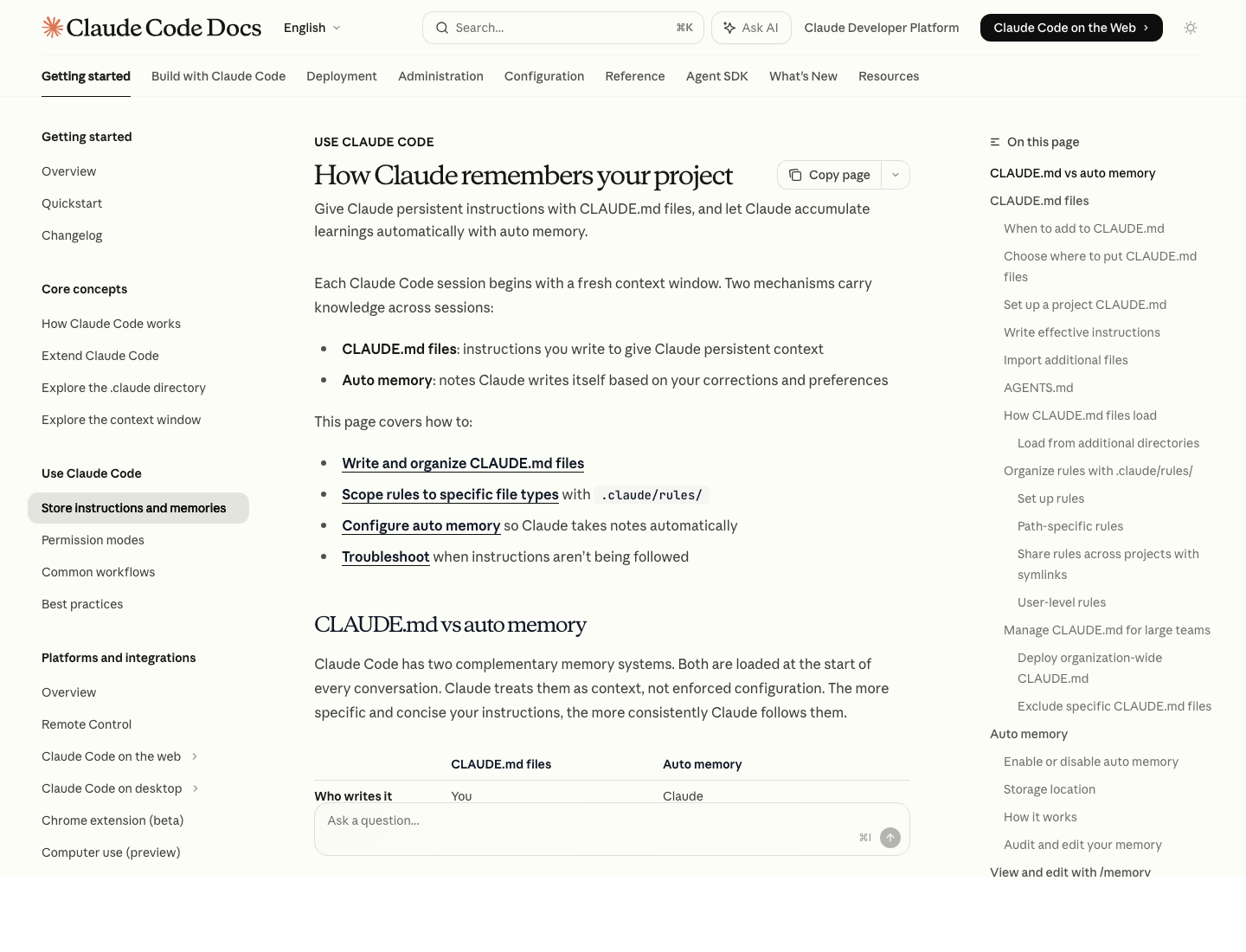
来源:How Claude remembers your project
哪些内容应该写进 CLAUDE.md
稳定规则写进 CLAUDE.md,不要留在对话里漂。
适合写进去的内容:
- build、test、lint、dev 的常用命令
- 每次都会用到的项目结构说明
- repo 专属的命名规范和代码风格
- 工作流约束,比如“改完必须先跑测试”
- 重要提醒,比如“这个服务本地依赖 Redis”
不适合写进去的内容:
- 一次性的 bug 诊断
- 临时分支上的短期备注
- 更适合做成 skill 的长流程说明
- 大段原样粘贴的文档资料
Claude 的官方 memory 文档现在写得很清楚:CLAUDE.md 是你主动写下来的持久指令,auto memory 是 Claude 自己积累出来的学习记录。
哪些内容不要塞进 CLAUDE.md
很常见的误区,是把 CLAUDE.md 当成杂物箱。
文件一大,不只是更费上下文,还会降低遵循效果。Anthropic 的文档明确提到:越短、越具体的指令,Claude 通常越容易稳定遵守。
一个很实用的判断方式:
- 事实和规则,放进
CLAUDE.md - 长流程,放进 skill
- 详细参考资料,拆成导入文件
- 一次性协作内容,留在当前对话
如果真的需要更多结构,就用 @path import 把大文件拆开,而不是把所有东西堆进一个巨大的 CLAUDE.md。
遇到这 5 种症状,分别该怎么处理
1. “Claude 把前面说过的规则忘了”
最好的处理方式:
- 如果这是持久规则,写进
CLAUDE.md - 如果任务还没结束,就用
/compact,并明确告诉它要保留什么
一个很关键的官方细节是:/compact 之后,项目根目录下的 CLAUDE.md 会重新从磁盘读入,但只存在于聊天里的规则,不会神奇恢复回来。换句话说,光靠聊天重复强调,其实比你想的更脆弱。
2. “Claude 还活着,但脑子里全是无关历史”
最好的处理方式:
- 用
/compact,并给出聚焦指令 - 如果这些历史已经没有价值,直接
/clear
最差的处理方式:
- 在同一条已经发臭的对话里继续拉扯 30 轮
3. “我每天都在重复解释同一套 repo 规则”
最好的处理方式:
- 打开
/memory - 更新
CLAUDE.md - 把小的个人习惯交给 auto memory
这正是 memory 系统该干的活。
4. “会话 technically 还能用,但质量已经开始掉”
最好的处理方式:
- 先看
/context - 在变得彻底混乱之前先 compact
Claude Code 在上下文逼近上限时,确实会先清掉旧的工具输出,再做总结。但通常你主动出手,会比等系统自己兜底更稳。
5. “我想保留这次结果,但不想背着整段聊天继续走”
最好的处理方式:
- 只 compact 那些真正重要的结论
- 或者导出当前对话,然后重新开始
要保留的是结果,不是通往结果的全部废话。
一套足够稳的长会话模式
如果你经常用 Claude Code 做长时间调试、重构或排查,这套模式已经够用了:
- 一开始就把任务定窄。
- 项目级规则写进
CLAUDE.md。 - 尽量用
@file引用,不要狂贴大段内容。 - 在会话变得难看之前先看
/context。 - 每完成一个阶段,就考虑
/compact,不要只在出问题后才用。 - 任务真的变了,就直接
/clear。
很多人嘴里的“token 限制问题”,其实用这 6 步就能提前规避掉大半。
应该怎么理解 Auto Memory
Auto memory 很有用,但它不是项目记忆的替代品。
按照 Anthropic 文档的定义,它更像 Claude 给自己记的笔记:常用命令、调试经验、偏好、重复出现的模式。它会通过项目的 memory 目录在会话开始时被加载,其中 MEMORY.md 是那个简短入口。
更合理的分工是:
CLAUDE.md负责你有意识写下来的规则- auto memory 负责 Claude 慢慢学到的习惯和发现
如果某条规则真的很重要,重要到一旦忘了就会影响结果,那就不要赌 auto memory,直接手写进 CLAUDE.md。
快速检查清单
- 这还是同一个任务吗,还是应该直接
/clear? - 当前会话是不是已经值得
/compact了? - 我有没有告诉
/compact哪些内容必须保留? - 这条规则是不是应该进
CLAUDE.md,而不是只留在聊天里? - 我现在保存的是稳定规则,还是一堆一次性噪音?
- 我有没有在质量明显下降之前先看
/context?