GPT Image 2 是什么?一篇看懂 OpenAI 爆火图像模型的玩法教程
从概念澄清、能力边界到爆款案例与提示词模板,快速看懂 GPT Image 2 到底强在哪,以及怎么把它真正用起来。
GPT Image 2 是什么?一篇看懂 OpenAI 爆火图像模型的玩法教程
从概念澄清、能力边界到爆款案例与提示词模板,快速看懂 GPT Image 2 到底强在哪,以及怎么把它真正用起来。
先把名字讲清楚
如果你最近在 X、微信群或者各种 AI 圈讨论里频繁刷到 GPT Image 2,先不用急着背型号。
更实用的理解是:
它指向的是 OpenAI 这一代明显更强的图像生成能力,尤其是在文字排版、信息图、结构化画面和连续改图这几件事上。
至于“GPT Image 2”这个名字本身,至少在 2026 年 4 月 18 日 这个时间点,社区叫法和 OpenAI 对外公开的官方型号名,并不是完全一致的。
按 OpenAI 公开信息来看:
- 2025 年 3 月 25 日,OpenAI 发布了 4o Image Generation,把更强的图像生成能力带进 ChatGPT。
- 2025 年 4 月 23 日,OpenAI 在 API 里上线了
gpt-image-1。 - 2025 年 12 月 16 日,OpenAI 又发布了新版 ChatGPT Images,并在 API 里提供
gpt-image-1.5。
所以现在大家口中的“GPT Image 2 爆火”,更准确的理解方式是:
大家在讨论的是 OpenAI 新一代图像能力的实际表现,而不一定是在讨论一个已经被官方正式命名为 gpt-image-2 的公开 API 型号。
读这类教程时,只要别把下面三件事混成一件事就够了:
- ChatGPT 里的新版 Images
- API 里的
gpt-image-1.5 - 社区流传的 “GPT Image 2”
先把这个概念理顺,后面看玩法、测效果、抄提示词都会顺很多。

这张拼图式封面,基本可以看作这一波 GPT-image2 玩法传播的缩影。
先看 7 个有原帖可追溯的案例
很多模型升级,讨论两天就过去了。
但这一波 GPT Image 2 之所以能持续刷屏,一个很直接的原因就是:
它第一次让很多人产生了同一种感觉:这不只是“会画图”,而是已经能开始做带文字、带结构、带版式的成品。
下面这 7 张图,都是这一轮传播中最有代表性的案例。能追到原帖来源的,文中都附上了链接;原帖里能确认的提示词,也一并整理出来了。
1. 真实风景日历
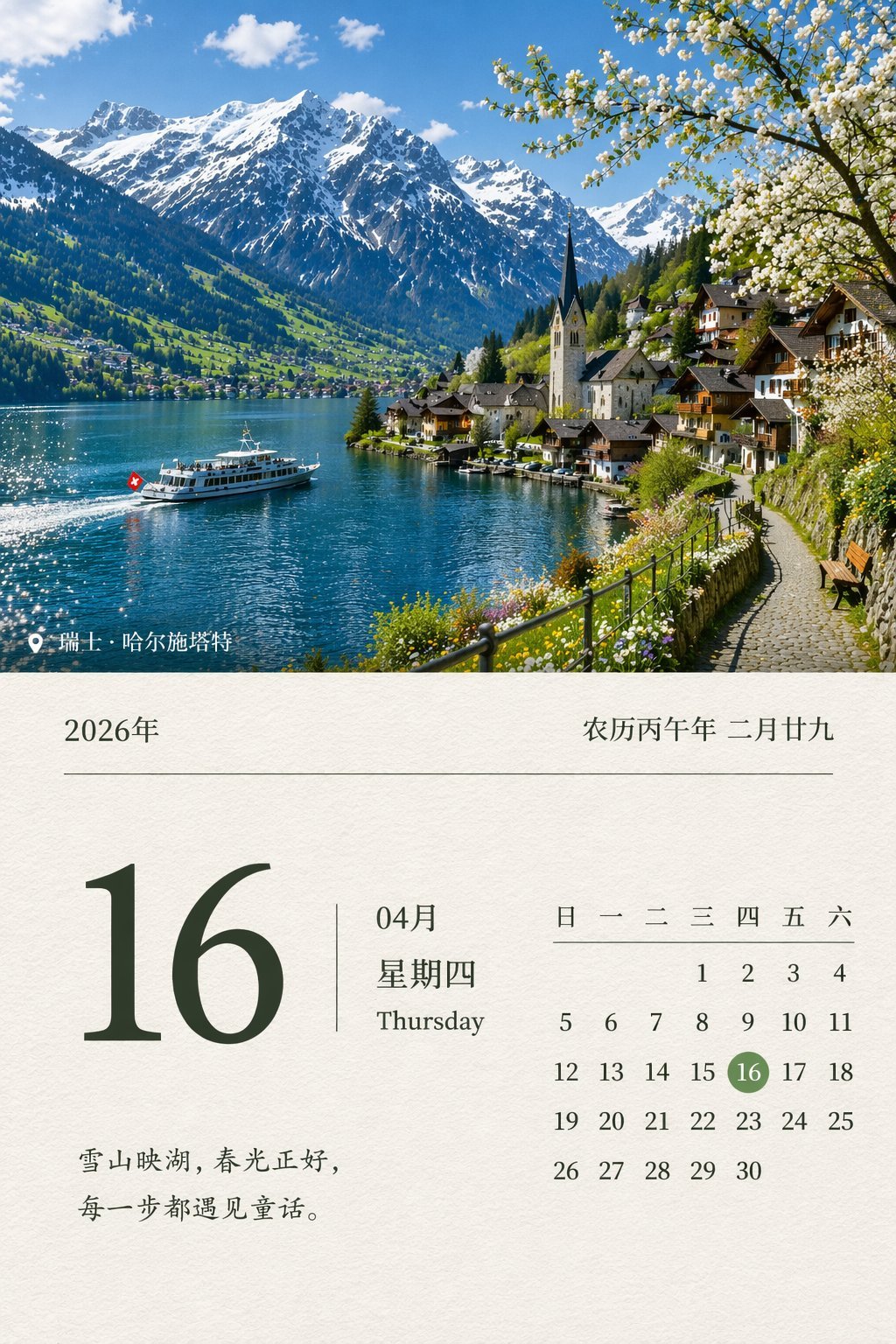
这类图为什么容易出圈?因为它同时考验了日期准确性、版式、真实摄影感和中文排版。
来源推文: WY (@akokoi1)
原帖公开的提示词:
设计一张2026年4月16日的真实风景日历
可直接扩写成更稳的版本:
设计一张 2026 年 4 月 16 日的真实风景日历海报。画面主体是一张高质量自然风景摄影,日期信息清晰可读,版式像真实日历封面,中文排版准确,整体高级、安静、自然,不要乱码,不要多余装饰。
2. GitHub 项目秒变宣传海报

这一类案例最能说明 GPT Image 2 的价值,因为它不是“凭空画一个东西”,而是把已有信息重新组织成视觉物料。
来源推文: 歸藏(guizang.ai) (@op7418)
原帖能确认的信息: 作者说自己“只给了项目的 GitHub 链接,然后让它生成卡片式的互联网宣传图”,图里的信息基本都对。
适合照抄的提示词写法:
基于这个 GitHub 项目链接里的真实信息,生成一张卡片式互联网宣传海报。
要求:
- 4:5 竖版
- 主标题突出
- 用 4 个功能卡片概括核心能力
- 底部放项目地址和二维码区域
- 中文文案准确
- 整体像 SaaS 产品宣发图
- 配色干净、现代、有科技感
3. 二次元 / VTuber 风格 Logo
![]()
这张图证明的不是“模型会写几个字”,而是它能把装饰字、品牌感和角色气质一起做出来。
来源推文: みどり🐲Midori Tatsuta (@midori_tatsuta)
原帖能确认的信息: 作者明确说这是用 GPT-image2 直接生成的 VTuber 风格 Logo。
可复用提示词:
为虚构 VTuber 角色设计一组二次元潮流 Logo。
要求:
- 日系偶像 / VTuber 视觉风格
- 每个 Logo 都有清晰可读的日文主标题
- 风格分别偏梦幻、暗黑、清爽、魔法书、街头电音
- 线条干净
- 有商业可用的完成度
- 背景纯白,像品牌提案板
4. 一张图裂变成完整 MV 分镜

这类案例很能代表 GPT Image 2 的“结构能力”。它不只是在画角色,而是在把角色设定、场景设定、镜头分解、机位说明整理成一张图。
来源推文: WTR (@wtry1102)
原帖能确认的信息: 作者先用 ChatGPT 设计 Seedance2 的 MV prompt,再把角色设定和背景交给 GPT Image 2,让它输出图解化的分镜设计图。
可复用提示词:
根据这组角色设定图和背景设定,生成一张 MV 分镜与镜头设计图。
要求:
- 顶部展示角色设定参考和场景鸟瞰图
- 中部拆成 3 到 4 个关键镜头
- 每个镜头写明机位、景别、动作和情绪
- 右侧补充镜头运动示意
- 整体像专业拍摄分镜板
- 所有文字尽量清晰可读
5. 高难度知识图 / 架构图
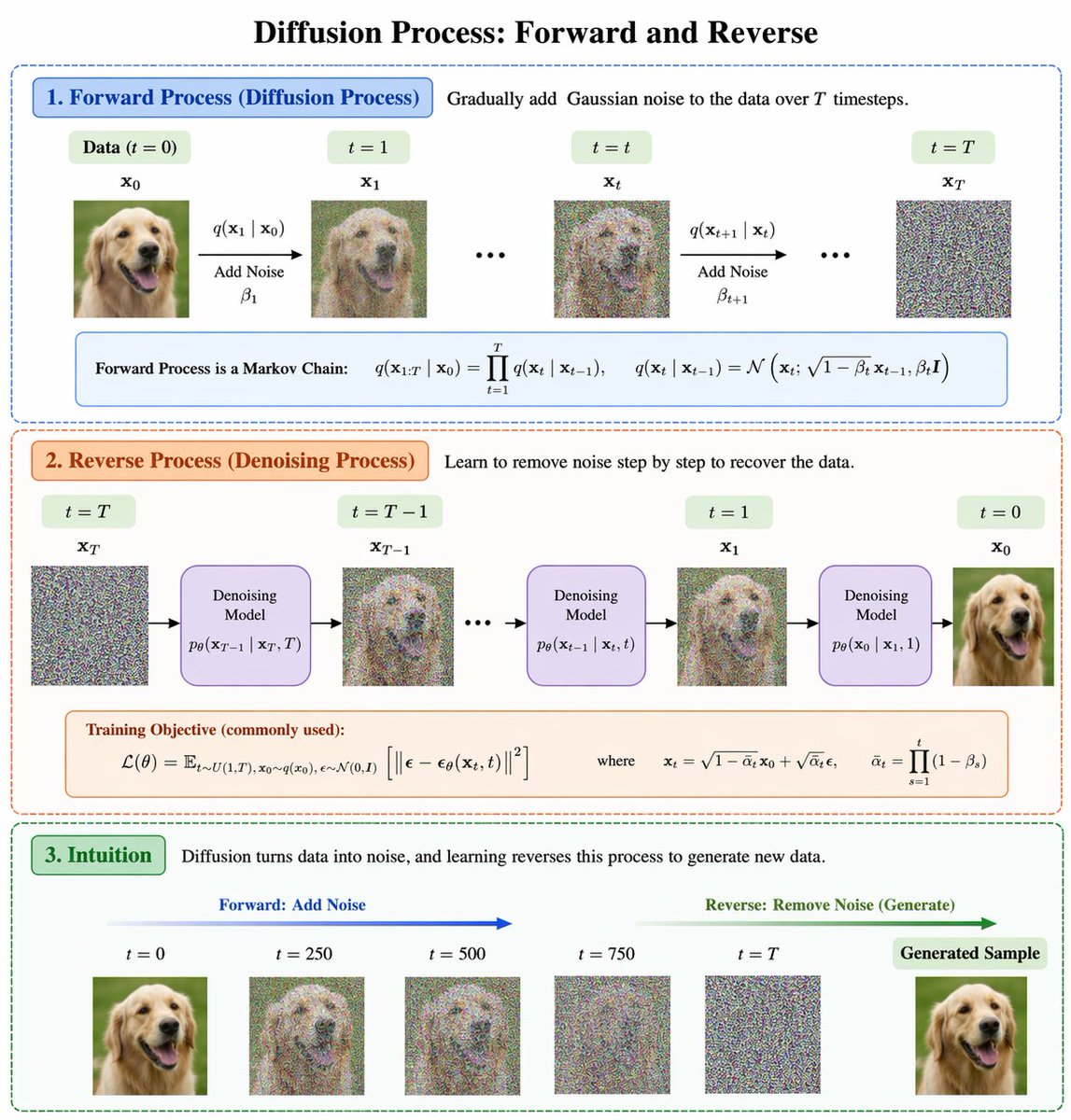
这类图过去最容易翻车,因为既要结构准确,又要标签清楚,还要让箭头关系看起来像真的课件或论文配图。
来源推文: BubbleBrain (@BubbleBrain)
原帖没有公开完整提示词,只表达了一个判断:GPT-Image-2 is a huge leap.
更适合拿来复现的提示词写法:
设计一张清晰、学术风格的流程图,主题是 “Diffusion Process: Forward and Reverse”。
要求:
- 顶部是总标题
- 中间分成 Forward Process 和 Reverse Process 两大模块
- 用箭头连接每一步
- 配上简短公式和说明文字
- 整体像机器学习课程讲义中的高质量信息图
- 文字清晰、结构严格、配色克制
6. 逼真的中文试卷

这是最容易让人直观感受到“文字能力升级”的案例之一。因为试卷这种版式,几乎没有模糊发挥空间。
来源推文: 秋风_irwin (@qiufenghyf)
原帖能确认的信息: 作者认为这张试卷不只是逼真,而且题目本身看起来也像真实题目。
可复用提示词:
生成一张逼真的高中数学试卷照片。
要求:
- 简体中文
- 像手机随手拍的真实纸质试卷
- 顶部有考试标题、总分、考试时间
- 正文是选择题和几何题混排
- 纸张有轻微透视和自然阴影
- 题干和选项尽量真实、清晰、可读
7. 大段中文书法 / 经文排版

这类图过去几乎是很多模型的噩梦。因为不仅字多,而且字形、密度、上下文一致性都很难控制。
来源推文: sundyme (@sundyme)
原帖能确认的信息: 作者特别强调,这张图的提示词并没有逐字写出整段心经文本,而是模型自己完成了大部分文字发挥。
适合尝试的提示词写法:
生成一幅古典东方佛经风格的立轴海报。
要求:
- 中央是大段竖向中文经文排版
- 上方有标题
- 四周有细腻、古画质感的佛教人物与纹样装饰
- 纸张和颜料有古朴质感
- 字体工整、密集、尽量避免乱码
GPT Image 2 为什么突然这么火?
原因很简单。
它把过去几代图像模型最容易翻车的几个点,明显往前推了一大截:
1. 文字终于更能看了
以前很多图像模型最大的问题,就是一旦画面里出现大段文字、海报标题、UI 标签、信息图注释,就很容易乱码。
而这波大家讨论 GPT Image 2,最集中的反馈就是:
- 海报上的标题更稳了
- 信息图里的标签更像“真的字”
- UI 页面、路线图、菜单、卡片文案更容易排得像样
这也是它在 X 上传播最快的原因之一。
因为“能把字做对”,直接决定它能不能从“玩具”进入“生产工具”。

这类信息图过去很容易出现文字糊掉、标签错位、层级混乱。现在至少在短文本和清晰结构里,成功率已经高得多。
2. 指令跟随能力更强了
你让它“生成一张海报”,很多模型都能做。
但你让它:
- 做成 4:5 竖版
- 主标题放顶部
- 中间是 3 个步骤
- 底部加 CTA
- 用米白色背景和红色强调色
- 保持极简科技感
这时候差距就出来了。
OpenAI 官方也明确把新版 Images 的重点放在了 stronger instruction following 和 more precise editing 上。
这意味着它更适合做:
- 电商主图
- 社媒海报
- 路线图信息图
- 产品 mockup
- 带文案的封面图
3. 世界知识和结构感更强
从 X 上的案例看,大家很爱拿它去做:
- 地图
- 解剖图
- 时间线
- 产品对比图
- 模拟页面
原因不是它“什么都绝对正确”。
而是它在很多需要结构化表达的任务里,比过去更像一个“懂内容的设计助手”。
OpenAI 官方文档对 GPT Image 的描述里,也专门强调了 world knowledge 和 detailed editing。
人体解剖图、世界地图、门店招牌、YouTube 页面,这些都不是“随便画一张图”能糊弄过去的题目。
4. 连续编辑体验更实用
新版 ChatGPT Images 和 GPT Image 系列的另一个强点,是它不仅能从零生成,也更适合基于已有图继续改。
比如:
- 换背景
- 改文字
- 保留人物脸不变,换服装和场景
- 保留产品主体,换光线、角度、风格
这类需求以前很容易越改越崩。
现在则更接近“对着设计师改稿”。
它到底适合做什么?
如果你只是想知道实用方向,我建议优先看这 5 类。
1. 带大量文字的海报和封面
这是它现在最容易出圈的玩法。
特别适合:
- 公众号封面
- 小红书图文封面
- 活动海报
- 产品介绍图
- 课程宣传页
2. 信息图和路线图
比如把一段很抽象的内容,变成:
- 时间线
- 三步法
- 对比表
- 产品功能图
- 学习路径图
你会发现它在“把复杂信息视觉化”这件事上,已经很能打了。
3. 电商图和品牌物料
官方 API 文档里提到的落地方向就包括:
- 营销素材
- 商品图
- 品牌内容
- 设计编辑
如果你做电商、自媒体、SaaS 官网,这块很值得用。
4. UI mockup 和伪截图
X 上流传很广的一类案例,就是让它生成:
- App 首页
- Dashboard
- 虚构人物社交主页
- 历史人物“发推页面”
这一类图传播性极强。
因为它天然适合做“第一眼就想转发”的内容。
5. 基于原图做精修和重绘
这其实比纯生成更实用。
很多人最后真正会高频使用的,不是凭空生成,而是:
- 传一张原图进去
- 告诉它只改哪一部分
- 连续迭代 2 到 4 次
这样出图效率通常更高。
真正好用的提示词,要怎么写?
很多人一上来就问“有没有神 prompt”。
其实更重要的是结构。
我建议你用这套 6 段式写法:
GPT Image 提示词结构
- 任务目标
- 主体内容
- 版式布局
- 画面风格
- 文字内容
- 限制条件
你可以直接套这个骨架:
Create a [asset type] about [topic].
Main subject: [what should appear in the image].
Layout: [where title, body, labels, icons, CTA should go].
Style: [minimal / editorial / cinematic / product-ad / infographic / Apple-like / vintage].
Color palette: [specific colors].
Text in image:
"..."
"..."
"..."
Requirements:
- all text must be legible
- clean typography
- strong visual hierarchy
- no gibberish text
- no watermark
- high detail
为什么这样更稳?
因为你不是只告诉模型“要什么”。
你还在告诉它“怎么摆、怎么写、哪些地方不能错”。
怎么把这些案例转成你自己的 prompt?
看完上面的真实案例,你大概会发现一个规律:
真正容易出效果的,不是空泛地说“帮我画一张很酷的图”,而是明确告诉模型你要产出的成品类型。
最常见的 4 种写法就是:
- 日历 / 海报 / 宣发图
- Logo / 标题字 / 品牌板
- 分镜图 / 流程图 / 路线图
- 试卷 / 截图 / 拟真页面
也就是说,先写“这是什么成品”,再写“里面该有什么”,成功率会高很多。
你可以直接套这个骨架:
请生成一张 [成品类型]。
主题:
[你要表达的主题]
画面内容:
[画面里必须出现的主体、元素、结构]
版式要求:
[标题在哪里,内容分几块,是否需要箭头、卡片、二维码、边栏等]
文字要求:
[图中必须出现的文字]
风格要求:
[写实 / 日系 / 互联网产品海报 / 学术信息图 / 古典东方等]
限制条件:
- 所有文字尽量清晰可读
- 不要乱码
- 保持真实排版逻辑
- 细节完整
如果第一轮已经接近想要的结果,不要急着推倒重来。
更有效的做法通常是继续补一句:
Keep the overall composition unchanged. Only improve the typography, fix incorrect text, and make the layout more polished.
3 个实战建议,比“神 prompt”更重要
1. 先短,后长
第一轮不要把 prompt 写成 500 字作文。
先把:
- 主题
- 构图
- 风格
- 关键文字
写清楚。
如果第一轮方向对了,再追加修订指令。
2. 把文字内容单独列出来
想要图里文字更稳,不要把文案埋在大段描述里。
最好直接写成:
Text in image:
"标题"
"副标题"
"按钮文字"
这对海报、信息图、UI 页面特别有用。
3. 学会用“保留不变”
连续编辑时,最重要的一句话往往不是“改成什么”,而是:
Keep the composition and subject unchanged. Only update the headline and color palette.
这会明显减少模型把整张图推倒重来的概率。
现阶段也别神化它
虽然它很强,但也别把它想成万能。
目前仍然常见的问题有:
- 长段中文有时还是会出错
- 表格特别复杂时容易崩
- 多区域小字一多,仍然可能混乱
- 一些专业知识图并不保证完全正确
所以最稳的使用方式不是“一次生成完美终稿”。
而是:
先出结构,再局部修,再改文字,再做精修。
这才是它真正适合进入工作流的方式。
最后怎么理解 GPT Image 2?
如果你只记一句话,我建议记这个:
GPT Image 2 火,不只是因为它更会画,而是因为它开始更像一个能听懂需求、能排版、能改稿的视觉助手。
这意味着 AI 图像生成,正在从“拼手气”走向“可协作”。
这一步很关键。
因为从这里开始,真正能跑起来的不是炫技图,而是:
- 内容封面
- 电商物料
- 说明图
- 信息图
- mockup
- 可迭代的设计草稿
如果你现在就想上手,我建议你先从这两个方向开始:
- 做一张 带 3 行短文案的海报
- 做一张 有清晰层级的信息图
这两个最能快速感受到 GPT Image 2 这一波能力升级。
参考资料
- OpenAI: Introducing 4o Image Generation
- OpenAI: Introducing our latest image generation model in the API
- OpenAI Docs: Image generation guide
- OpenAI Docs: GPT Image 1.5
- OpenAI: The new ChatGPT Images is here
- OpenAI Help: ChatGPT Images FAQ
- X 传播案例汇总参考:@crayon1267 的相关帖文摘要